Newsgroups: bit.listserv.edi-l From: lynn@netcom18.netcom.com (Lynn Wheeler) Subject: Account Authority Digital Signature model Date: Mon, 5 Jan 1998 01:44:42 GMTX9 is working on x9.59 electronic payments in the x9a10 working group.
in support of x9.59, i've been working an account-authority digital signature model ....
Three digital signature models are described; the original "offline" model and two newer "online" models. It is expected that the two "online" models become the prevailing modes of operation for online financially-related and/or electronic commerce transactions.
Digital Signature Model 1:
--------------------------
The traditional PKI infrastructure talks about issuing certificates that are signed by a certificate authority which attest to the:
validity of the public key preferably checking validity of the private key possibly some identity information of the entity that the certificate is issued to.
The associated PKI-use model has an entity "digitally signing" a document with their private key and "pushing"
the transaction/document the digital signature a copy of their digital certificate
to another party. The receiving party presumably will validate the authenticity of the digital-signature and the originator's public key via the contents of the associated digital certificate. Originally the contents of the digital certificate was assumed to be sufficient such that digital signature validation could be performed without any additional electronic transmissions. As the methodology matured, it became apparent that more and more complex verification mechanisms were needed, if nothing else various status could have changed between the time that the certificate was originally manufactured and the current moment. Certificate revokation lists (CRLs) were one such development in an attempt to partially address the issue of current real-time certificate status in the offline verification model.
Digital Signature Model 2 (or account-based PKI):
------------------------------------------------
This is a proposed implementation for the X9.59 framework. An account-holder registers their public-key (and verification of their private-key use) with the account authority. In a transaction the account-holder digitally signs a transaction and pushes the transaction, the digital signature, and the account number. Eventually the transaction arrives at the account authority and the digital signature is verified using the public key registered in the account record. The account authority maintains the status of the holder's public key as part of the overall account management process. The transaction therefore requires neither a certificate nor some complex status methodology (like CRLs) since the account authority maintains current validity status as part of account management.
This is effectively the X9.59 check and credit-card models where the receiving entity/business forwards the payment instruction to the account issuing institution. The payer's digital signature is forwarded by the receiving businness to the issuing institution; the issuing institution authenticates the digital signature using the registered public-key in the account record. No signed certificate attesting to the validity of the public key is required since the public-key is on file in the account record.
An account-authority performs the majority of the same functions performed by a certificate authority, but the processing costs are absorbed by the standard business process ... not by charging for the issuing of a certificate. It is possible that an account-authority might also wish to become a certificate authority since it potentially could be undertaken at less then 5% additional business costs.
Digital Signature Model 3 (positive authentication):
---------------------------------------------------
This is actually a slight variation on #2, although it bears some superficial resemblance to #1. The initial designs for positive authentication PKI, used the credit-card authorization model to replace CRLs. However they kept the rest of the infrastructure; the originator's certificate was still pushed around with the transaction. The receiver validated the CA's signature on the certificate, then sent off a certificate status request and validated the CA's signature a second time on the status response (and then validated the original digital signature).
Model #3 looks very much like model #2 in that the originator's certificate is not pushed around with the transaction. However, rather than sending the digital signature in the authorization request, just the certificate identifier (account number) is sent to the CA. The CA signs a status response that includes information regarding the real-time validity of the account along with a copy of the account's public key. In effect the real time status response becomes a mini-certificate. The entity that will act on the transaction now only has to verify the CA's signature on the status response (i.e. mini-certificate, it doesn't also have to verify the CA's signature on a certificate manufactured at some point in the past). It then uses the public-key returned in the status response to validate the originator's digital signature.
Superficially this resembles digital certificate model #1 but the actual operation is much more like model #2. Including the account's public-key in the real-time status response creates, in effect, a mini-certificate. It also eliminates a redundant and superfluous validation of the CA's digital signature (on both the manufactured digital certificate and the real-time status responses).
The biggest operational difference between #2 and #3 is that the account authority verifies the originator's digital signature in #2 and in #3 it just returns the value of the account's public key for the requester to validate a digital signature. If the requester can send the document or even the secure hash of the document to the account authority along with a copy of the digital signature, then the account authority can verify the digital signature. If not, the request just identifies the account and the mini-certificate is returned allowing the requester to validate the digital signature.
The positive authentication model presents a number of revenue opportunities for the CA to charge for various levels of detail returned in real-time status responses (and/or approval levels associated with the transaction).
Conclusion
----------
Digital signature model #1 was originally developed to allow "offline" verification of a digital signature. A manufactured certificate was pushed along with the signed document and the digital signature could be verified using just the contents of the certificate that was passed along with the document.
Offline signature verification using a certificate manufactured several months in the past (and by implication relying on status that was several months stale) turned out to be inadequate for various kinds of transactions. This has led to the definition of more complicated processes in the certificate-push model in an attempt to provide more timely status and verification.
There has also been the implicit assumption that only the certificate authority is performing registration services for digital signature processes. As the concept of digital signatures have become more acceptable, it has also becoming apparent that existing business processes (already performing account registration functions) can be simply extended to add public-key registration.
Revisiting the PKI basic architecture, it became apparent that there were several optimizations possible if it was recognized there were significant numbers of online PKI operations (compared to earlier models that started out assuming offline PKI and later tried to graft online features afterwards).
The offline validation and certificate push model is still valid for some types of transactions and shouldn't be precluded. However, real online validation (models #2 and #3) can eliminate some number of redundant and superfluous operations.
It should be noted that the "offline" validation is different than the "offline" purchasing referred to in X9.59. X9.59 assumes that the purchuser/payer can be offline and transmits an order and payment instructions via methods like email (not requiring real-time, online interaction with the business). In the validation process, there is an issue whether the business is also offline at the point that it approves the transaction. If the business is offline, then it needs a payer's certificate to validate (and authorize) the payer's transaction. If the business is online, then either model #2 or model #3 is used (and it is not necessary for the consumer to push the certificate with the transaction). Furthermore, in the case of model #2, either the business can perform its own PKI registration function and/or it can rely on a financial account infrastructure to have implemented a PKI registration function.
It is expected that digital signature models #2 and #3 become the prevalent modes of operation for at least financial transactions.
Denial of service attack addenda
--------------------------------
There is a hypothetical case (that can be made for certificate pushing in the online world) which is associated with anonymous denial of service attacks. The existing Internet infrastructure provides significant opportunities for electronic terrorists to anonymously (and/or under assumed identity) launch denial of service attacks (flooding a web site with enormous number of bogus requests). These are undertaken with the assumption that it is nearly impossible to trace the source of the attack.
One of the techniques for dealing with denial of service attacks is to recognize and eliminate bogus requests as soon as possible. If a certificate is pushed with a request then some preliminary screening of requests can be performed during initial processing and possibly eliminate some number of bogus transactions.
The downside is that public key operations are extremely expensive; preliminary screening of a request using the certificate (and still doing the online validation later) could be more expensive than allowing bogus transactions through and recognizing them via the standard mechanism.
Most of these are simple band-aid solutions. The real problem is that
existing Internet backbone operation makes it simple to impersonate a
network address. As a result it is usually very difficult to trace
back to the originator of an electronic attack.
--
Anne & Lynn Wheeler | lynn@netcom.com
Newsgroups: bit.listserv.edi-l From: lynn@netcom20.netcom.com (Lynn Wheeler) Subject: payment and security taxonomy/glossary Date: Mon, 5 Jan 1998 16:14:21 GMTi also have been working on payment taxonomy/glossary, file is payment.htm
it is in directory at ftp.netcom.com/pub/ly/lynn
it the same directory there is also taxonomy/glossary on security: secure.htm
the other files in the directory are the stuff i do on ietf rfc (some is basis for section 6.10 in std1): rfcietf.htm
>>: files now at
>> https://www.garlic.com/~lynn/payment.htm
>> https://www.garlic.com/~lynn/secure.htm
>> https://www.garlic.com/~lynn/rfcietff.htm
--
Anne & Lynn Wheeler | lynn@netcom.com
| finger for pgp key
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: CP-67 (was IBM 360 DOS (was Is Win95 without DOS...)) Newsgroups: alt.folklore.computers Date: 12 Jan 1998 14:12:05 -0800CP/67 is coming up on its 30th birthday. The last week in January, 1968, John Harmon and Dick Baelis come out to the university that I was at and installed CP/67. I worked on it sporadically over the next two years.
I participated at the product announcement at the spring (March) 1968 Houston Share Meeting. Later that spring, IBM held a one week class on CP/67 for prospective customers in LA. I was induced to help teach the class, even though I was an undergraduate and had my own classes to take.
One of the things I remember was rewriting the terminal handling and included support for tty/ascii terminals. I had done some fancy programming for the 2702 terminal controller ... which seemed to work ... but the IBM CE told me wasn't supportable since there was (effectively) flacky wiring in the 2702 that would make what I was trying to do unreliable (dynamic terminal type identification, 1050, 2741, & tty).
Somewhat as a resort, four of us set out to build our own terminal controller around an early minicomputer and our own hand built bus&tag wire-wrapped channel attachment board. Somewhere this activity is credited with originating the IBM OEM controller business. I was recently told that a decendent of the company that made the minicomputer we used ... was selling a product with what appeared to be the same wire-wrap board well into the early 80s.
I also redesigned and rewrote the virtual memory manager, dispatcher, process scheduler, I/O superviser, and several other components of the operating system. For the virtual memory manager, I designed and implemented the original clock algorithm (the clock algorithm was the subject of a stanford phd thesis nearly 15 years later
There was one specific implementation that supported >70 concurrent mix-mode users with a 95 percentile response for interactive transactions of <1sec (this is a machine with 768k bytes of real memory and less than a 0.5mip processing power ... say something in the class of a 286).
--
Anne & Lynn Wheeler | lynn@garlic.com, lynn@netcom.com
| finger for pgp key
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: CP-67 (was IBM 360 DOS (was Is Win95 without DOS...)) Newsgroups: alt.folklore.computers Date: 12 Jan 1998 14:19:02 -0800correction, i should have said that CP/67 product is coming up on its 30th announcement anniversary.
--
Anne & Lynn Wheeler | lynn@garlic.com, lynn@netcom.com
| finger for pgp key
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: VSE or MVS Newsgroups: alt.folklore.computers Date: 03 Feb 1998 21:23:15 -0800an important issue to consider wmvs is that its paradigm is batch processing ... not interactive; the implication of that is when programs are design & written ... it was NOT assumed there were people to talk to; somewhat as a result it tended to be assumed that circumstances would have to be handled programmatically rather than just reporting an error message to a user.
for sophisticated servers, it can make quite a more complex programming environment that rather than writing out a error message and (possibly) quiting ... software had to be written to handle every possible contingency and recover from it.
one of the things that i've periodically wished for is the ability to "on error" all possible ICMP responses ... and appropriately handle them; this would require some mechanism to both associate incoming ICMP packets with outgoing activity ... as well as being able to push them up the protocol stack.
the batch processing paradigm has made it a somewhat problamatically interactive (& user friendly) platform ... but it sure makes for rock solid industrial strength server/services platform.
it didn't come about magically ... some of it evolved over long period of time. at one time I was associated with very hostile i/o environment (hundreds of errors per day that commercial shop might see one per year) ... that if they brought mvs up ... it would crash within 15 minutes. I undertook to completely rewrite an i/o supervisor that would never crash &/or loop ... making the code absolutely bullet proof.
--
Anne & Lynn Wheeler | lynn@garlic.com, lynn@netcom.com
| finger for pgp key
From: lynn@garlic.com (Anne & Lynn Wheeler) Subject: x9.59 electronic payment standard Newsgroups: gov.us.topic.ecommerce.standards Date: 25 Feb 1998 00:45:42 -0500x9a10 subgroup is working on x9.59 electronic payment standard that can be used for any kind of account-based financial transaction (check, ach, debit, credit, etc).
references and pointers to the work can be found at
--
Anne & Lynn Wheeler | lynn@garlic.com, lynn@netcom.com
https://www.garlic.com/~lynn/ | finger for pgp key
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: OS with no distinction between RAM and HD ? Newsgroups: alt.folklore.computers Date: 04 Apr 1998 11:35:10 -0700some of the early single-level-store OS tended to have poor trashing characteristics ... not only did all data look like was part of memory it was used that way ... adaptive pattern algorithms didn't exist and there were no hints like file open/close.
cross-over when memory was cheaper/faster than disk probably came some time in the 70s. virtual memory prior to that was a way of cramming only the used part of the program into real memory w/o the developer having to incure all the trouble of doing overlays.
after the cross-over ... disk caches were a method of using memory to compensate for the fact that CPUs&memory were improving much faster than disks (in at least one processor line ... relative system performance of disks declined by a factor of five over a fifteen year period between 68 & 83 ... i.e. processor/memory improved by a factor of 50*, disk improved by a only factor of 10* ... therefor disk relative system performance declined by factor of 5*).
I started noticing it around '77/'78 time-frame when trying to upgrade dynamic adaptive algorithms ... and "scheduling to the bottleneck" ... probability that filesystem was primary sysem bottleneck had signficantly increased in the ten years that i had been working in the area.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: DOS is Stolen! Newsgroups: alt.folklore.urban,alt.folklore.computers,seattle.general,comp.misc Date: 04 Apr 1998 21:24:51 -0700actually some number of the people that worked on CMS (545 tech sq & burlington mall) moved to DEC in the mid-70s and worked on VMS.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: ** Old Vintage Operating Systems ** Newsgroups: alt.folklore.computers,alt.sys.pdp10 Date: 17 Apr 1998 19:20:25 -0700compare&swap was done back around 71 or so (actually CAS was the engineer's initials ... it took another 3 months to come up with the compare&swap to go w/CAS) ... there was delay of six months or so getting it into the machine architecture because of being tasked to invent a way where it would be used in non-smp applications (thus was born the description of using it in application code doing stuff like updating single threaded lists and counters w/o locking code or data).
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: ** Old Vintage Operating Systems ** Newsgroups: alt.folklore.computers,alt.sys.pdp10 Date: 25 Apr 1998 14:37:43 -0700my first experience was with monitor was 1401 MPIO (i believe stood for multiprogram input/output) ... it was card deck that booted into 1401 and handled the unit record spooling for 709 ibsys (card->tape, tape->printer/punch); i.e. 709 ibsys ran fortan jobs tape<->tape.
summer job i got as undergraduate (after taking a 2hr semester intro to programming class) was to recreate the 1401 MPIO monitor on 360/30 ... so the 2540/1403 unit record gear could be switched to the 30 ... and the 30 could be used for both 360 testing and still provide front-end functions for the 709.
i designed and implemented my own interrupt handler, device drivers, i/o supervisor, multi-tasking supervisor, error recovery, operator interface, memory manager, etc. ,,, it had to support all of the 1401 MPIO functions ... including being able to distinguish between bcd/ecbdic and column binary cards (i.e. had to separately feed & read ... since if not bcd ... would have to reread in column binary) ... was able to concurrently overlap card->tape and tape->print/punch using dynamic buffering of all available memory on the 30.
i used a BPS loader to read monitor into 360/30 and take over all functions of the machine. when MPIO wasn't running ... 360/30 booted OS and was used for OS testing (and/or recompiling my program).
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: OS with no distinction between RAM a Newsgroups: alt.folklore.computers Date: 25 Apr 1998 18:23:13 -0700i admit to knowing nothing about other virtual machine implementations ... but the ibm one dates from 1965 (many of the people working on it had worked on ctss) ... and i first worked on it as an undergraduate in 68. it had a micro-kernel that supported virtual memory, demand paging, partitioning of resources ... and simulation of many ibm mainframe instructions. prior to availability of the first engineering model of ibm 370 ... a version was modified to simulate the new 370 instructions in order to start testing operating systems. since it provided fully functional (virtual) machine equivalent to the functions available on the real machine ... one or more other operating systems could be booted and run as if they were running on individual real machines.
detailed early history can be found at:
https://www.leeandmelindavarian.com/Melinda#VMHist
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: S/360 operating systems geneaology Newsgroups: alt.folklore.computers Date: 25 Apr 1998 18:53:42 -0700actually TSS was rather slow ... when I first encountered it as an undergraduate ... it would barely handle 4 concurrent users doing interactive edit. on the same hardware, cp/67 would support 32 users doing mix-mode interactive program development, compile, and test concurrently (with the 32 users getting better response than the 4 under tss). I know of no time that tss/360 ran faster than cp/67 ... and/or tss/370 ran faster than vm/370 (it wasn't even a contest to compare against svs or mvs).
initial conversion of mvt was to SVS ... single virtual storage ... basically mvt kernel and application address space (which was nomally limited to the size of real machine) ... was laid out in a single 16mbyte (24-bit address) virtual address space. early releases were little more than running MVT with a 16mbyte virtual machine size under vm/370. SVS was upgraded to MVS (multiple virtual storage) ... which allowed each program its own 16mbyte address space (rather than having to execute all concurrent programs in the same address space).
MVS retained MVT kernel code that directly addressed application memory ... as a result the 16mbyte address space was (initially) partitioned into the 8mbyte kernel space and 8mbyte application space. All virtual address spaces shared the same 8mbyte kernel space (with the 8mbyte appliation space being unique).
This caused a problem for subsystem services ... which were actually system services operating outside the kernel in application space. They were as used to directly addressing application data (as real kernel services) when providing services. When called by a normal appliation program ... these subsystem services no longer had direct addressability to application data (since they now resided in different virtual address spaces). This gave raise to cross-memory services ... special instructions that allowed addressing of memory in other address spaces.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: S/360 operating systems geneaology Newsgroups: alt.folklore.computers Date: 26 Apr 1998 20:57:17 -0700it was on tss/360 on 768k 360/67 ... they tried running on 512k but it wouldn't boot, so had to upgrade to 768k (tss had originally told the customers to configure the machines for 256k real memory ... so 768k was threefold increase).
tss/360 had two problems barely handling 4 users ... bloated kernel size so there was little room left in 768k for paging program virtual memory ... and lack of dynamic adaptive algorithms (which it shared with later svs and mvs systems). When i did an algorithm ... i alwas only did as much work as the configuration and workload required. tss/360 had neat trick that when a task entered interactive queue, its pages were streamed/migration from the 2311 to the (4mbyte) 2301 fixed head disk ... the program was then demand paged from the 2301 fixed head disk while running interactively. when the program dropped from the interactive queue ... the pages on the 2301 was streamed/migrated back to the 2311. This streaming/migration occurred whether there was any constrained resources for the 2301 or not.
there is this great story that after tss was decommuted and the tss group dropped down to 15-20(?) ... there was only a single person in all the scheduling function ... who now noticed that every routine called the scheduler. Typically what happened was some interrupt/system call into the kernel was made and execution would go from module to module performing the indicating piece of work (with every module calling the scheduler). Supposedly this person then went to the implementation I had done for a cp/67 rewrite I had done as undergraduate ... attempting to do only a single call to the scheduler per pass thru the kernel. Supposedly this change culled an avg. of million instruction pathlength out of tss/360 system calls (million in the story would seem to be something of an exaggeration ... but it makes for great retelling).
It wasn't until about a year after I graduated that I got cp/67 on 768k 360/67 to 80 users, unconstrained mix-mode workload, 90% interactive response <1sec. Fixed kernel requirements for tss was larger than cp/67 ... and the working set of all tss applications & compilers were larger than the comparable ones on cp/67 (and tss pathlengths were longer than mine ... even when they copied the code) ... this configuration while still only 768kbyte memory did have three 2301 fixed head disks (for a total of 12mbytes fast paging memory) and 40 2314 disk drives (for paging overflow and user/application files).
I would expect tss/360 on a 768k machine might only have 40-60 4k pages of real memory left for virtual paging. In fact, I seem to remember a later tss report of some study that tss/360 ran more than twice as fast on a dual processor 2mbyte machine compared to a single processor 1mbyte machine ... i.e. even at 1mbyte of real memory, real storage left to application virtual memory still resulted in quite a bit of page thrashing. A two processor machine doubled the real memory ... but since there wasn't a second kernel ... the amount of real storage available for virtual memory paging possibly increased by a factor of five ... which would reasonably account for thruput more than doubling. Otherwise, if you look at the processor hardware, memory/processor cycle time increased when going from a single processor configuration to a dual processor configuration (to allow for bus abertration on the memory bus) ... and SMP kernel operation had additional overhead handling lock contention/resolution; nominal based on pure hardware specs and kernel operation a two processor configuration should never be more than about 1.8* the thruput of a single processor (except possibly for the fact that severe memory constraint threshold was lifted).
originally the 360/67 had 2311 disk drives that held 7mbytes and were really slow access ... things helped a little when you could upgrade from 2311 to 2314 which held 29mbytes and had avg 4kbyte block access of 85.8 mills (60ms arm access, 12.5 avg rotational delay, .3mbyte/sec data transfer). the configuration that i worked on after i graduated had 40 of these drives (which was quite a large installation) ... or about 1.2gbyte aggregate.
I have hard time imagining a tss/360 2311 installation with several concurrent applications requiring 15-20mbytes of virtual memory each.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: S/360 operating systems geneaology Newsgroups: alt.folklore.computers Date: 27 Apr 1998 20:56:28 -0700timesharing, ctss, 360, mac, csc, 360/67, tss, etc ... see
https://www.leeandmelindavarian.com/Melinda/25paper.pdf
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: S/360 operating systems geneaology Newsgroups: alt.folklore.computers Date: 27 Apr 1998 21:16:33 -0700misc. stuff from van vleck (1401, multics, cp/67, etc):
https://www.multicians.org/thvv/
... 360/67 ... in addition to number of green cards ... i've got a fan-fold blue reference card for the 360/67 (229-3174). somewhere i've got an early srl when it was still called the 360/62 (single processor, dual processor, and quad processor configurations). the base was 360/60 ... when memory was upgraded (before customer ship) the 360/60 was renamed 360/65 and the 360/62 was renamed 360/67. Somewhere along the way ... they dropped support for the quad processor configuration.
note/update:
I remember reading an early document about 360/6x machine with virtual
memory having one, two, and four processors. I sort of had vaque
recollection that it was model number other than 360/67.
however, i've subsequently been told that 360/60 was with 2mic memory
and 360/62 was with 1mic memory. both models never shipped, and were
replaced with 360/65 with 750ns memory. the 360/67 then shipped as
360/65 with virtual memory ... only available in one (uniprocessor)
and two processor (multiprocessor) configurations
https://www.garlic.com/~lynn/2006m.html#50 The System/360 Model 20 Wasn't As Bad As All That
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: S/360 operating systems geneaology Newsgroups: alt.folklore.computers Date: 28 Apr 1998 07:54:38 -0700very few mention LLMPS ... lincoln labs multiprogramming supervisor ... supposedly on which michigan terminal system (MTS) was originally built. for MTS reference:
http://www.itd.umich.edu/~doc/Digest/0596/feat02.html
https://web.archive.org/web/19970103225657/http://www.itd.umich.edu/~doc/Digest/0596/feat02.html
i may even have a LLMPS around someplace (some place as old 360/62 srl?) ... it was little more than fancy MPIO/monitor ... most of the tasks available were simple unix record & tape utilities.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: S/360 operating systems geneaology Newsgroups: alt.folklore.computers Date: 28 Apr 1998 08:03:55 -0700another trivia ... the internal network (something else originated at CSC) had more nodes and more users than arpanet/internet up until possibly '85. cross-over in machines mainly because of large number of single-user workstations that were being connected.
GML (precursor to SGML and HTML) also originated at CSC (and while most people believe GML standards for generalized markup language ... it actually is initials of three people that worked on it).
compare&swap also originated at CSC (hardware instruction for atomic concurrency control ... and more than simple barrier/lock; it also started out as the engineer's intials CAS ... for which something had to be found to go with the letters).
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: lynn@garlic.com (Anne & Lynn Wheeler) Subject: Re: S/360 operating systems geneaology Newsgroups: alt.folklore.computers Date: 29 Apr 1998 13:25:34 GMTthere were two fixed-head "drums" that were nearly identical mechanically ... the 2303 and the 2301. the 2303 read/write single head at a time; the 2301 did read/write interleave on four heads simultaneously (4* transfer rate). Doing single page transfers at a time resulted in similar thruput for the two devices (because of same rotational delay) ... about 80 transfers per second. Chaining of page i/o requests could increase the 2301 thruput to about 300/sec ... effectively saturating the channel (i/o bus). multiple 2301s on the same channel wouldn't increase the transfer thruput .. but on duplex configuratons splitting multiple 2301s across two channels would provide ability to do sustained transfer of 600/sec.
initial cp/67 delivered in jan. 68 had no chaining and i/o queuing was fifo. i rewrote the I/O system adding chaining for the 2301 and ordered seek queueing to the disk i/o subsystem. The original page replacement was effectively fifo. I invented one and two hand clock for page replacement, as well as inventing my own dynamic adaptive scheduler (original scheduler look possibly like CTSS and not too different from some "modern" unixes).
The tss crew did a lot of studies with performance tuning witch doctors of the table driven scheduler under lots of different environments, workloads, configurations, etc. My objective was to make all of that automatic and dynamic ... and up the level of the art to capacity planning (i.e. for instance cpu hogs got penalizd only if there was cpu contention, page hots got penalized only if there was page contention ... theory that i had which was dynamically scheduling to the bottleneck).
Many of the page replacements algorithms attempted to tune to be nearly as good as true LRU. I also invented a variation of two-hand clock that beat LRU and still had very, very short pathlength. It drove a lot of the sysprogs crazy. The good sysprogs tend to be very state/control oriented ... nothing happened unless it was specifically programmed for. The two-hand variation actually switched from LRU and random based on whether LRU was performing well or badly (i.e. there are some potentially shortlived, spontaneous, possibly pathological conditions where an application is chasin its tail and LRU is the exact wrong replacement algorithm). Because of the way he code was implemented ... the pages effectively self-organized into LRU or random ... based on whether LRU was performing well or badly. This was done with no code testing &/or making the switch ... almost an interesting side-effort of the way i sequenced the code. Furthermore, the degree of LRU or randomness was effectively proportional to how well LRU was working. Not being able to see it in explicit code really confused a lot of the best sysprogs who weren't use to data structures being dynamically self-organizing.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: lynn@garlic.com (Anne & Lynn Wheeler) Subject: Re: Reviving the OS/360 thread (Questions about OS/360) Newsgroups: alt.folklore.computers Date: 30 Apr 1998 13:28:59 GMTthere is html copy of POP up on one of the ibm sites ... i thik you can find it via one of the search engines.
a big thing that i found about mvt/mvs was its batch paradigm. if i'm rolling out any sort of business critical sevice ... i would like to programatically handle all problems. The batch paradigm in mvt/mvs assumed that no people were connected to a program and allowed optional traps on almost every possible conceivable condition. by contrast the desk top paradigm of most of the "open systems" have tended to assume there is a person connected to the program and can get by with sending a message an letting a person decide something. If i'm trying to deploy pilot web servers cost of making it industrial strength might not be justified ... but if i'm really figuring on it being a business critical application ... i would really like to plan for every contigency ... rather than getting a trouble call that results in a NTF (no trouble found).
simple example is tcp/ip protocol. there are ICMP error responses for a lot of conditions ... but the tcp/ip stack does't allow the option of reflecting the ICMP error condition back up the stack of the originating application (in fact, there is no obvious way of even associating an incoming ICMP error packet with an outgoing packet ... say an opaque value in the header of every outgoing ip packet that was copied into an ICMP error packets. As a result application layer just times out and punts on the problem.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
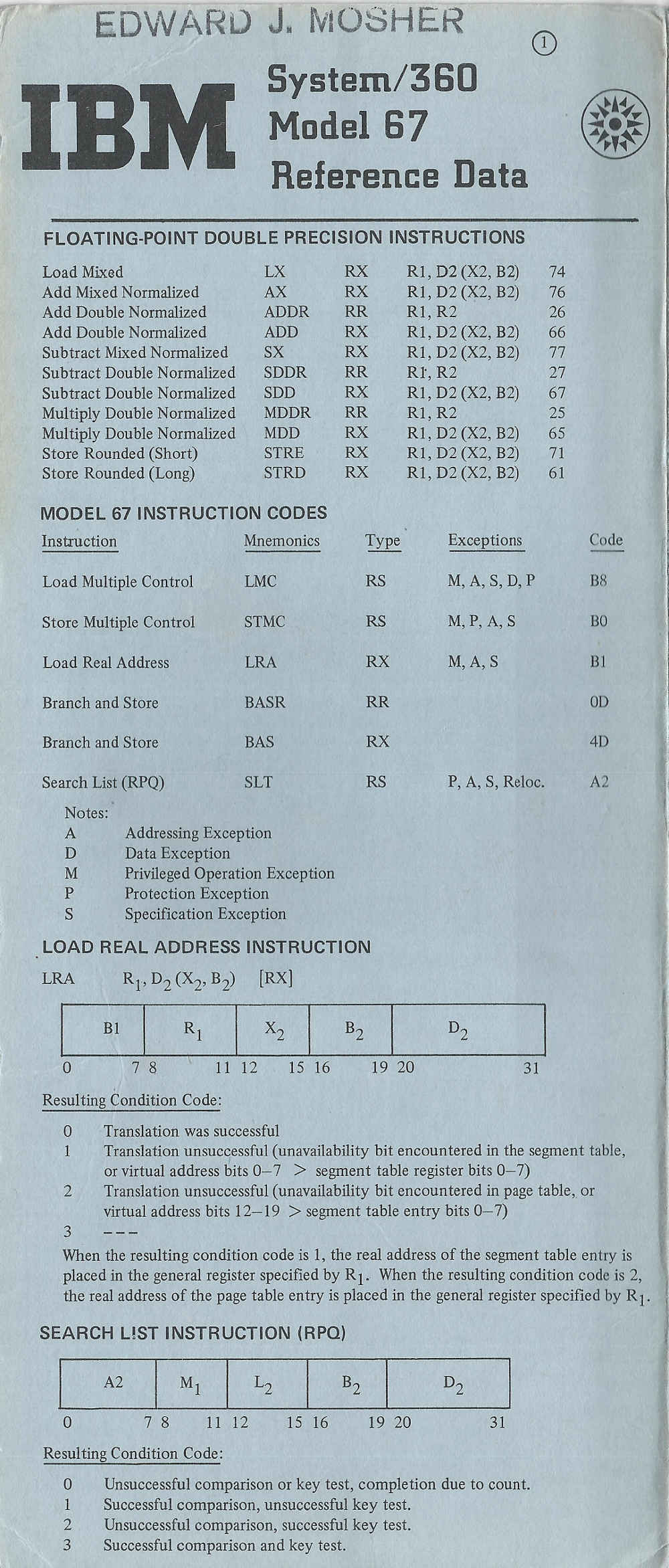
From: lynn@garlic.com (Anne & Lynn Wheeler) Subject: Re: S/360 operating systems geneaology Newsgroups: alt.folklore.computers Date: 01 May 1998 00:38:57 GMTSLT ... or search list was used by a number of places for things like free storage/space allocation (cp/67 was one) ... running down threaded list of blocks looking for match (based on some conditions) ... the free storage application in cp/67 got subsumed by the subpool implementation around 1971 (i.e. even at almost one storage cycle per block check on list ... it was still significantly slower than software doing LIFO thread for most used blocks).
also it isn't as complex as luther's radix partition tree stuff in the current POP (find the current online HTML POP at ibm and check out the tree instructions).
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Reviving the OS/360 thread (Questions about OS/360) Newsgroups: alt.folklore.computers Date: 02 May 1998 16:22:09 -0700try
http://ppdbooks.pok.ibm.com:80/cgi-in/bookmgr/bookmgr.cmd/BOOKS/DZ9AR004/CCONTENTS
for something even neater than SLT ... look at luther's radix partition tree instructions in the current POP
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Reviving the OS/360 thread (Questions about OS/360) Newsgroups: alt.folklore.computers Date: 02 May 1998 18:25:55 -0700POP was a subset of the "red book" .. which was possibly twice as large as POP .. with POP as subset section within the red book. It was implemented in gml (starting 1971?; precursor to sgml and html) and conditional was printed/displayed either the "full" red book ... or just the POP portions. red book tended to have unannounced instructions as well as lot of architectural and engineering justifications for instructions.
attached is posting I made here some years ago on os.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
Newsgroups: alt.folklore.computers Subject: CP/67 & OS MFT14 Date: Sun, 3 Apr 1994 17:51:11 GMT Lines: 112
In response to various inquiries, attached is report that I presented at the fall '68 SHARE meeting (Atlantic City?). CSC had installed CP/67 at our university in January '68. We were then part of the CP/67 "announcement" that went on at the spring '68 SHARE meeting (in Houston).
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
OS Performance Studies With CP/67
OS MFT 14, OS nucleus with 100 entry trace table, 105 record
in-core job queue, default IBM in-core modules, nucleus total
size 82k, job scheduler 100k.
HASP 118k Hasp with 1/3 2314 track buffering
Job Stream 25 FORTG compiles
Bare machine Time to run: 322 sec. (12.9 sec/job)
times Time to run just JCL for above: 292 sec. (11.7 sec/job)
Orig. CP/67 Time to run: 856 sec. (34.2 sec/job)
times Time to run just JCL for above: 787 sec. (31.5 sec/job)
Ratio CP/67 to bare machine
2.65 Run FORTG compiles
2.7 to run just JCL
2.2 Total time less JCL time
1 user, OS on with all of core available less CP/67 program.
Note: No jobs run with the original CP/67 had ratio times higher than
the job scheduler. For example, the same 25 jobs were run under WATFOR,
where they were compiled and executed. Bare machine time was 20 secs.,
CP/67 time was 44 sec. or a ratio of 2.2. Subtracting 11.7 sec. for
bare machine time and 31.5 for CP/67 time, a ratio for WATFOR less
job scheduler time was 1.5.
I hand built the OS MFT system with careful ordering of
cards in the stage-two sysgen to optimize placement of data sets,
and members in SYS1.LINKLIB and SYS1.SVCLIB.
MODIFIED CP/67
OS run with one other user. The other user was not active, was just
available to control amount of core used by OS. The following table
gives core available to OS, execution time and execution time ratio
for the 25 FORTG compiles.
CORE (pages) OS with Hasp OS w/o HASP
104 1.35 (435 sec)
94 1.37 (445 sec)
74 1.38 (450 sec) 1.49 (480 sec)
64 1.89 (610 sec) 1.49 (480 sec)
54 2.32 (750 sec) 1.81 (585 sec)
44 4.53 (1450 sec) 1.96 (630 sec)
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
MISC. footnotes:
I had started doing hand-built "in-queue" SYSGENs starting with MFT11. I would manually break all the stage2 SYSGEN steps into individual components, provide "JOB" cards for each step and then effectively run the "stand-alone" stage2 SYSGEN in the standard, production job-queue.
I would also carefully reorder the steps/jobs in stage2 (as well as reordering MOVE/COPY statements for PDS member order/placement) so as to appropriately place data on disk for optimal disk arm-seek performance.
In the following report, the "bare-machine" times of 12.9 sec/job was typically over 30 seconds/job for a MFT14 built using standard "stand-alone" SYSGEN process (effectively increase in arm-seek elapsed time). Also, the standard OS "fix/maintenance" process involved replacing PDS-members which resulted in destroying careful member placement. Even with an optimally built system, "six months" of OS maintenance would resort in performance degrading to over 20 secs/job.
A non-optimal built OS system actually would make CP/67 performance look "better" (i.e. ratio of CP/67 times to "bare-machine" times). CP/67 overhead (elapsed time increase) was proportional to simulation activity for various "kernel" activities going on in the virtual machine. I/O elapsed time was not affecting by running under CP/67. Keeping the sumulation overhead fixed, but doubling (or tripling) the elapsed time with longer I/O service time would improve the CP/67/bare-machine ratios.
The modified CP/67 was based on numerous pathlength performance changes that I had done between Jan of 1968 and Sept of 1968, i.e. reduce CP/67 elapsed time from 856 sec. to 435 secs (reduction in CP/67 pathlength CPU cycles from 534secs to 113secs).
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Reviving the OS/360 thread (Questions about OS/360) Newsgroups: alt.folklore.computers Date: 03 May 1998 05:12:21 -0700oops ... typo ... missing "b" in cgi-bin ... should be:
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Fear of Multiprocessing? Newsgroups: alt.folklore.computers Date: 05 May 1998 07:52:53 -0700360/62 was designed for 1, 2, & 4 ... switch to new core(?) became 360/67; with switch to 67, documentation dropped references to 4-way.
manned obital laboratory (MOHO?) had a custom 3-way 360/67 tho.
smp 360/67 had a "channel director" box that provided switches that could offline/online &/or configure all the cpus, memory banks, and channel I/O. for the 3-way, the channel director box was customized so all the switches could be under software control for fault isolation/management.
360/370/390 has currently gone to 8-way (although there is a 10-way clone). big problem in the 390 lineage is the cache strong memory consistency ... requiring cache to operate significantly faster cycle than rest of machine.
in '74/'75 worked on 5-way ... both the kernel software and hardware boxes; never shipped.
in '75/'76 switched to 16-way 370 with relaxed memory consistency; got canned ... in part because most of the company couldn't come to grips with practical implications of slightly relaxing memory consistency in SMP environment (i.e. indistinguishable from slight variations in race condition ... possible because of differences in cache miss/hit between different cpus). it also got division president really upset since we had co-opt'ed his best mainline engineers to moonlight on something different.
after 16-way got canned ... I retro-fit all my kernel changes to vanilla VM/370 release 3 system (before vm had SMP support) and deployed it at HONE (1501 calfornia in palo alto) on cluster of 2-way SMPs; in late 77, cluster support was upgraded to be largest single system image cluster ... supposedly in the world at the time (HONE was system that supported all the marketing and field service people). Later around '79, HONE was upgraded with clusters in Dallas and Boulder (for disaster survivability ... all the scare of earthquakes in cal).
there is separate geneology for the custom SMP 360s that went in 30+ years ago for FAA air traffic system.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Fear of Multiprocessing? Newsgroups: alt.folklore.computers Date: 05 May 1998 18:07:16 -0700correction ... S/390 G3/G4 now have 10-way SMP
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Merced & compilers (was Re: Effect of speed ... ) Newsgroups: comp.arch Date: 08 Jun 1998 12:00:29 -0700power/pc is evolution of 801 (RISC) from the early to mid-70s. one characteristic of base 801 was there was absolutely no memory consistency ... and somewhat policy of not supporting smp. 16-bit romp 801 chip showed up in early 80s ... and saw deployment in pc/rt product. Blue Iliad was early '80s 32-bit 801 chip ... but didn't manage to appear in any products. RIOS was 32-bit chip set that made it out in rs/6000 (and other products) in late 80s.
Late 80s saw collobration work between Motorola and IBM to (effectively) take core RIOS and add some cache consistency and other features mapped to more compact chip design with lower power requirements (somewhat simplified ... but imagine IBM RIOS core and motorola 88k bus). 601 was the first(?) power/pc ... mainly 6xx have been in the workstation & server markets. There are also 4xx and others in power/pc genre that are targeted for things like embedded controller markets.
360/370/390 are CISC mainframe architecture that has been around since early '60s.
801s have (all/mostly) been CMOS. Relatively recently IBM has introduced 390 mainframes built using CMOS.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Merced & compilers (was Re: Effect of speed ... ) Newsgroups: comp.arch Date: 09 Jun 1998 08:22:52 -0700oops ... sorry about missing detail ... from berkeley cpu site:
first 370 cmos I saw in early to mid-80s in two models ... pc/at
co-processor card ... and a separate box connected to pc/xt. were
in the 100 KIPS range. also from berkeley cpu site:
Like the DEC VAX, the S/370 has been implemented as a
microprocessor. The Micro/370 discarded all but 102 instructions (some
supervisor instructions differed), with a coprocessor providing
support for 60 others, while the rest are emulated (as in the
MicroVAX). The Micro/370 had a 68000 compatible bus, but was otherwise
completely unique (some legends claim it was a 68000 with modified
microcode plus a modified 8087 as the coprocessor, others say IBM
started with the 68000 design and completely replaced most of the
core, keeping the bus interface, ALU, and other reusable parts, which
is more likely).
More recently, with increased microprocessor complexity, a complete
S/390 superscalar microprocessor with 64K L1 cache (at up to 350MHz, a
higher clock rate than the 200MHz Intel's Pentium Pro available at the
time) has been designed.
sorry about the use of the "recently" with respect to 390.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Merced & compilers (was Re: Effect of speed ... ) Newsgroups: comp.arch Date: 10 Jun 1998 09:38:30 -0700... oh yes, the ROMP 40bit virtual memory was a misnomer (as was the 50+bit rios virtual memory). the architecture uses 32bit virtual addressing ... 16 "segments" (in the higher order 4 bits of the 32bit virtual address) with 28bit bits of segment address offset (i.e. 16 fixed sized 256mbytes segments).
in some of the segment/page architectures with segment and page tables ... the virtual memory look aside hardware associates an entry with a specific virtual address space by taging it with the real address of the segment (or in some cases page) table. 801 uses inverted tables ... so there isn't a real segment or page table address that can be used to differentiate different virtual address spaces.
ROMP defined a 12bit "identifier" used to differentiate different virtual address spaces. The 12bit "identifier" plus the "28bit" virtual segment offset ... results in 40bits ... if you added up all the possible different virtual address spaces (i.e. 4096) times the size of each one (256mbytes). Both the ROMP 40bit number and the RIOS 50+bit number are values that are somewhat orthogonal to the 32bit virtual addressing supported.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Drive letters Newsgroups: alt.folklore.computers Date: 30 Jun 1998 18:12:41 -0700I believe TSO was available on later MVT releases, SVS, and MVS.
CMS & CP/40 were both developed concurrently at Cambridge Science Center (4th floor, 545 tech sq). CP/40 was developed for a model 40 that had custom dynamic address translation hardware.
When 360/67 became available ... CP/40 was converted to CP/67 (this occurred somewhat earlier than the first MVT release showed up ... circa R12 or R13 ... MVT really wasn't usable until R15/R16 ... a combined OS release). The conversion of CP/67 to VM/370 occurred about the same time as TSO work was going on (the first 370 machines were shipped w/o dynamic address translation enabled; SVS ... single virtual storage and MVS ... multiple virtual storage ... required dynamic address translation hardware).
I believe CERN benchmarked MVS/TSO and VM/CMS circa 1974 ... it was interesting in that the copy of the benchmark report made available to IBM was promptly labled IBM Restricted Confidential ... and was only available on a need to know basis (at least inside IBM).
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Drive letters Newsgroups: alt.folklore.computers Date: 30 Jun 1998 21:14:25 -0700prior to TSO ... there were a number of CRJE and other "online" implementations for OS/360. While an undergraduate, I had written a CRJE modification to HASP-III thar run under MVT OS/18 ... that implemented the CMS editor syntax and supported 2741, 1050, and TTY terminals.
I wasn't even a close port of the CMS editor code ... since CMS was a "single-user" system that normally ran in a dedicate CP virtual machine. Applications were all dedicated w/o threading or multitasking.
HASP-III under MVT was fully multi-threaded/tasking implementation ... so I about that only thing that I used from the CMS editor was the syntax.
I was able to borrow the terminal driver code that I had written for CP/67 ... I had modified the original CP terminal code to add support for TTY/TWX terminals.
TSO provided somewhat improved integration of the terminal environment and program scheduling ... that the run of the mill CRJE systems which preceeded TSO.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Drive letters Newsgroups: alt.folklore.computers Date: 01 Jul 1998 12:52:05 -0700could have been Rosato ... who was manager of the CMS group for much of its history (recently I seem to remember seeing him having email address over at MIT associated with VM support).
last thing my wife and I did before leaving IBM was skunk works for cluster operation (when she was six years old ... she was talked into going to POK to be responsible for loosely-coupled, while there she invented and wrote the architecture document for peer-coupled shared data ... some of which is now starting to appear in parallel sysplex offerings).
we did initial cluster prototypes and subcontracted much of our development to several former Athena people ... who took over the CSC 101 main street location after CSC was shutdown (far enuf down the road hardly could be called in the sq).
we were also on target to deploy some 128-system fiber channel cluster scale-up configurations in database applications ... until hardware got diverted to IBM Kingston and announced as their product.
several of the strongest backers of cluster operation today were some of the most vocal against cluster 10 years ago (and the early work that both my wife and I did in the cluster area go back 25 years or so).
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: PowerPC MMU Newsgroups: comp.arch Date: 01 Jul 1998 14:27:12 -0700problems from the early 70s was proliferation of virtual & shared objects ... with limitation of only 16 ... or even 256 simultaneous objects in single virtual memory ... quickly ran into application combinatorial limitations (problems like possibly not being able to run word processor to document formater to hardcopy output).
In the 70s, it was partially alleviated by combining multiple applications/programs into single virtual object. PPC did some of the same stuff, calling them shared libraries.
801 precursor to power/powerpc made 16 segment register trade-off based on the assumption that the 16 segment register virtual memory design point was a closed system ... that operated w/o execution time protection domain (protection verification was done by compiling and binding processes); inline application code could as easily switch segment register contents as it might switch general/addressing register contents .... and therefor the limitation of 16 simultaneous virtual objects was not considered a serious limiation (anymore than being limited to 16 general purpose registers is viewed as possible limitation for addressing application memory). Absolute worst case was that every time an address value was loaded into a general purpose register ... a value might also have to be loaded into a segment register.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Drive letters Newsgroups: alt.folklore.computers Date: 04 Jul 1998 07:21:43 -0700when cp/67 was first being distributed it just had support for 2741 & 1052 as login/terminal device. i was undergraduate at university and we had these tty devices ... so rewrote the console handler to add tty support & mapped "break" key into the 2741 attention key function. does anybody still use a keyboard with a break key on it?
"userid" to "userid" early forms of email on the same machine starting seeing around '68 or so. between userids on different machines starting seeing late '70 or early '71. I remember being on a business trip in europe around '74 trying to hack my way thru networks back to the states to read my email (sales, admin, & field support were somewhat online ... and when european hdqtrs moved from NY to Le Defense ... I hand carried cloned operating system and software to europe as part of the move).
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: ... cics ... from posting from another list Newsgroups: alt.folklore.computers Date: 10 Jul 1998 23:02:55 -0700... post from vm mailing list ..
... and a follow-up post from me ...
as another total aside ... while I was working
on CP/67 and other things (four of us built
our own control unit ... some place we are blamed
for originating the IBM OEM control unit market)
as an undergraduate ... we were also an original CICS
beta-test site (library had grant from ONR).
I remember shooting a number of CICS BDAM bugs ....
they had tested for a specific BDAM file
configuration ... but library had slightly
different structure ...
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: ... cics ... from posting from another list Newsgroups: alt.folklore.computers Date: 10 Jul 1998 23:22:58 -0700... along similar lines ...
From: Lynn Wheeler
To: ansi-epay@lists.commerce.net
Subject: Re: ISO8583 (credit-card) Flow ... ebcdic/ascii mapping ... addenda
The other issue that shows up with doing public key operations in &/or
around mainframes is the use of outboard public key accelerator
boxes. The outboard boxes can typically be accessed by LU6.2, TCP/IP,
or customer channel protocol. The functions performed can be as simple
as performing the digital signature verification when passed a hash,
an existing digital signature, and the presumed public key
(i.e. decrypt the digital signature and compare the resulting value
with the hash). Slightly more complex is passing the signed data (in
correct format) and the outboard box calculates both the hash and
performs the digital signature verification (somewhat driving up
bandwidth requirements, but removing the hash calculation from the
mainframe).
Standard IBM mainframe tcp/ip product has had a design point of half
the thruput of LU6.2 .... making neither TCP/IP nor LU6.2 a great
choice for this function ... for any high thruput areas.
One of the issues is the traditional open system I/O paradigm
involving buffer copy operations (also shared by some of the mainframe
telecommunication protocols) ... where the data involved in the I/O is
copied between buffers at least once ... and possibly as many as 10-15
times. The traditional mainframe normal I/O thruput involve no buffer
copies (sometimes referred to by "locate-mode"). In the open system
arena this has shown up in recent years with POSIX asynch I/O
(although not part of the standard paradigm operation ... primarily
found with DBMS subsystems when doing DISK "raw" I/O to non-filesystem
drives). An issue that arises in the buffer-copy mode is that the
machine-cycles involved in doing the data copying can exceed the
machine-cycles involved in the instruction execution for the whole
application.
The original IBM TCP/IP product ocnsumed significant amount of 3090
CPU in order to achieve throughput of 44kbytes/sec. At that time, I
had implemented & integrated RFC1044 support which shipped in at least
some of the standard IBM TCP/IP products ... and benchmarked at Cray
Research between a 4341 and a Cray with sustained TCP/IP thruput at
IBM channel media spead (1mbyte/sec) using only nominal amounts of
4341 CPU utilization.
... snip ...
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Drive letters Newsgroups: alt.folklore.computers Date: 15 Jul 1998 23:07:09 -0700In article <6ndo8n$7v4@hyperion.mfltd.co.uk>, mww@microfocus.com (Michael Wojcik) wrote:
We did do some (not mainframe) when we were running a skunk works and did the prototype stuff for HA/CMP and needed to turn it out as a product. We worked with a couple friends (that had been in the Project Athena group who had left to form their own company) to develop and release HA/CMP. During that period, their company grew significantly and took over the space at 101 Main st. that had been occupired by ACIS/TCS/CSC (when they were all shutdown and the space became available).
Back in the mainframe world ... some more of her work is starting to now show up as parallel sysplex.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: What is MVS/ESA? Newsgroups: comp.programming Date: 18 Jul 1998 13:18:09 -0700for a look at the machine instruction set look at:
appendix gives various comparisons of changes along the way:
D.0 Appendix D. Comparison between ESA/370 and ESA/390 D.1 New Facilities in ESA/390 D.1.1 Access-List-Controlled Protection D.1.2 Branch and Set Authority D.1.3 Called-Space Identification D.1.4 Checksum D.1.5 Compare and Move Extended D.1.6 Concurrent Sense D.1.7 Immediate and Relative Instruction D.1.8 Move-Page Facility 2 D.1.9 PER 2 D.1.10 Perform Locked Operation D.1.11 Set Address Space Control Fast D.1.12 Square Root D.1.13 Storage-Protection Override D.1.14 String Instruction D.1.15 Subspace Group D.1.16 Suppression on Protection D.2 Comparison of Facilities E.0 Appendix E. Comparison between 370-XA and ESA/370 E.1 New Facilities in ESA/370 E.1.1 Access Registers E.1.2 Compare until Substring Equal E.1.3 Home Address Space E.1.4 Linkage Stack E.1.5 Load and Store Using Real Address E.1.6 Move Page Facility 1 E.1.7 Move with Source or Destination Key E.1.8 Private Space E.2 Comparison of Facilities E.3 Summary of Changes E.3.1 New Instructions Provided E.3.2 Comparison of PSW Formats E.3.3 New Control-Register Assignments E.3.4 New Assigned Storage Locations E.3.5 New Exceptions E.3.6 Change to Secondary-Space Mode E.3.7 Changes to ASN-Second-Table Entry and ASN Translation E.3.8 Changes to Entry-Table Entry and PC-Number Translation E.3.9 Changes to PROGRAM CALL E.3.10 Changes to SET ADDRESS SPACE CONTROL E.4 Effects in New Translation Modes E.4.1 Effects on Interlocks for Virtual-Storage References E.4.2 Effect on INSERT ADDRESS SPACE CONTROL E.4.3 Effect on LOAD REAL ADDRESS E.4.4 Effect on TEST PENDING INTERRUPTION E.4.5 Effect on TEST PROTECTION F.0 Appendix F. Comparison between System/370 and 370-XA F.1 New Facilities in 370-XA F.1.1 Bimodal Addressing F.1.2 31-Bit Logical Addressing F.1.3 31-Bit Real and Absolute Addressing F.1.4 Page Protection F.1.5 Tracing F.1.6 Incorrect-Length-Indication Suppression F.1.7 Status Verification F.2 Comparison of Facilities F.3 Summary of Changes F.3.1 Changes in Instructions Provided F.3.2 Input/Output Comparison F.3.3 Comparison of PSW Formats F.3.4 Changes in Control-Register Assignments F.3.5 Changes in Assigned Storage Locations F.3.6 Changes to SIGNAL PROCESSOR F.3.7 Machine-Check Changes F.3.8 Changes to Addressing Wraparound F.3.9 Changes to LOAD REAL ADDRESS F.3.10 Changes to 31-Bit Real Operand Addresses... also S/390 Parallel Sysplex at:
http://www.s390.ibm.com/products/pso/tkhilite.html
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: What is MVS/ESA? Newsgroups: comp.programming Date: 18 Jul 1998 13:29:38 -0700... and from a slightly related recent posting to alt.folklore.computers
Anne & Lynn Wheeler writes:
In article <6ndo8n$7v4@hyperion.mfltd.co.uk>,
mww@microfocus.com (Michael Wojcik) wrote:
> When I worked for IBM, I was a member of ACIS (Academic Computing)
> and later TCS (Technical Computing), I worked in the Cambridge Kendal
> Square building on the 7th and 8th floors; by that time ('88 to '91)
> the CSC had moved there also. While I was there one of my co-workers
> (whose name unfortunately escapes me at the moment) completed his 25th
> year at IBM, and at his reception mentioned that he had worked on
> CMS. Apparently "CMS" originally stood for "Cambridge Monitor
> System" but was officially renamed "Conversational Monitor System".
> The Cambridge site was also involved in a lot of Project Athena and
> early X Windows work - the CWM window manager, the AED display,
> etc.
when my wife was six years old & in the G'burg JES group, she was
talked into transferring to POK to be responsible for loosely-coupled.
while there she originated and wrote the architecture document for
Peer-Coupled Shared Data. Not much of it came from immediately
... IMS hot standby used some of it.
We did do some (not mainframe) when we were running a skunk works and did the prototype stuff for HA/CMP and needed to turn it out as a product. We worked with a couple friends (that had been in the Project Athena group who had left to form their own company) to develop and release HA/CMP. During that period, their company grew significantly and took over the space at 101 Main st. that had been occupired by ACIS/TCS/CSC (when they were all shutdown and the space became available).
Back in the mainframe world ... some more of her work is starting to now show up as parallel sysplex.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: digital signatures - defacto standard Newsgroups: talk.politics.crypto Date: 19 Jul 1998 07:56:26 -0700possibly not what you had in mind ... but account authority digital signature ... see my web pages.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: digital signatures - defacto standard Newsgroups: talk.politics.crypto Date: 19 Jul 1998 13:14:13 -0700and quite a strong case for EC-DSS can be made in account situations where the additional field might only increase the account record size by 10% rathar than doubling (or more) the account record size in various other implementations.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Comparison Cluster vs SMP? Newsgroups: comp.arch Date: 13 Aug 1998 07:40:13 -0700We spent some amount of time working on SCI stuff at the same doing HA/CMP and what we called fiber-channel cluster scale-up. Issues seemed to be hardware & software trade-offs ... as well as where particular hardware/software happens to be on various technology curves.
What surprised me was various current cluster names that were strongly opposed to it ... there was particular running argument at '91 SIGOPS about how COTS clusters would never make it in business/mission critical market.
Interesting thing is how long some of this stuff takes to come around. I got to work with charlie when he did compare&swap (i.e. something like 3 months were spent coming up with mnemonic that were his initials). Long ago and far away, I was working on 16-way SMP the same time my wife was inventing Peer-Coupled Shared Data ... original used only by IMS hot-standby ... but starting to see the light of day in parallel sysplex (i.e. os/390 & mvs world) ... the particular 16-way still hasn't shipped (and it has been over 20years; so my wife has better record than I do seeing things come to product; btw, she insists she only six years old when she did the work).
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: lynn@garlic.com (Anne & Lynn Wheeler) Subject: AADS, X9.59, & privacy Newsgroups: gov.us.topic.ecommerce.standards Date: 17 Aug 1998 00:45:42 -0800Public key digital signature technology can represent part of a strong authentication business process. However, it only represents a part of a business process infrastructure, also required is (at least) the binding of the digital signature to something that has meaning within a business process.
Account Authority Digital Signature Model AADS
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: early (1950s & 1960s) IBM mainframe software Newsgroups: alt.folklore.computers Date: 28 Aug 1998 13:11:36 -0700june 23rd, 1969 .... not only was software unbundled but also professional services; many shops were dependent on onsite ibm software engineers. However, it worked both ways, significant portion of ibm products were an outgrowth of these engineers working very closely with customers and then translating that experience & requirements into software solutions.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: early (1950s & 1960s) IBM mainframe software Newsgroups: alt.folklore.computers Date: 29 Aug 1998 17:40:20 -0700in both the sort run & long run it had a negative effect of the production of application software meeting customer requirements ... because it interrupted the integrated working infrastructure between the ibm technical people and customers (& customer day-to-day requirements).
i've claimed over the years that the majority of ibm software applications originated in operational shops ... not in software development groups. Some momentum continued after 6/23/69 because of the large number of internal ibm shops which continued to provide some integrated environment with real-world operational needs and software developers/programmers
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: 56,000-bit Keys? Newsgroups: sci.crypt Date: 06 Sep 1998 09:03:31 -0700basic issue is that multiplication becomes addition using logs ... with brute-force, pc power and field size have somewhat linear relationship ... key length is log-base-2 of the field size.
PC's 1,000 times more powerful is approx. 2**10 ... or 10 more bits (i.e. less than 66bits) ... not 1000 times more bits.
let's say PC's 1,000 times more powerful and a billion of them ... in aggregate 10**12; a little approx of 2**10 is about 10**3 ... then it is less than 2**40 ... or less than forty more bits ... i.e. 96bits.
to justify a 1000 times more bits would require PCs that 2**56000 times more powerful ... as mentioned in other posts this starts to get into the area where universe starts to impose limits.
reasonably reaching field-size of 2**128 (key length 128) ... attacks other than brute force on the field become much more interesting; being able to discern something about the key based on how it was generated and/or how it is used. if key use divulges information about the key ... using longer keys may or may not be able to compensate.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Why can't more CPUs virtualize themselves? Newsgroups: alt.folklore.computers Date: 28 Sep 1998 13:06:09 -0700cp/40 did it back circa 65/66 on 360m40. cp/67 did it on 360/67 (circa 67-73 or so). 370 could do it easily.
on the 360 & 370s ... there was a single instruction that could both change privilege status as well as addressing mode. It allowed virtualization kernels that were totally hidden from the stuff being virtualized. Later generations after the 360/370 got a lot more complex with their privilege modes ... and it was no longer possible to switch both privilege mode as well as addressing mode in a single instruction. For these later architectures explicit hardware support for virtualization was added (previously virtualization software support could be crafted built with standard machine architecture).
Current generation in the 360/370 lineage have added so much virtualization hardware support that it is possible to do it totally within what appears to be purely hardware .... i.e. LPAR or logical partitioning support (i.e. possibly a majority of the current installations have systems configured as two or more "virtual" systems using LPAR support ... representing possibly the majority of commercial dataprocessing that occurs today).
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: The god old days(???) Newsgroups: alt.folklore.computers Date: 13 Oct 1998 10:10:05 -0700... posted several times here and elsewhere ... from early report claiming that system I/O thruput had declined by factor of 10* (order of magnitude) between the late 60s and the early 80s.
workload was mixmode ... batch & interactive with 90% percentile response times between .1 & .2 seconds. There was report in the early 70s regarding human factors and different people's threshold to observe response times ... ranged from almost .25 seconds down to .10 seconds (i.e. being able to distinguish whether response had a delay or was effectively instantaneously). object was to try and keep interactive response below threshold for most people
Subject: Re: Virtual Memory (A return to the past?) From: lynn@garlic.com (Anne & Lynn Wheeler) Date: 1995/09/27 Newsgroups: comp.arch
.. some of you are probably getting tired of seeing this ... but a typical '68 hardware configuration and a typical configuration 15 years later
machine 360/67 3081K mips .3 14 47* pageable pages 105 7000 66* users 80 320 4* channels 6 24 4* drums 12meg 72meg 6* page I/O 150 600 4* user I/O 100 300 3* disk arms 45 32 4*?perform bytes/arm 29meg 630meg 23* avg. arm access 60mill 16mill 3.7* transfer rate .3meg 3meg 10* total data 1.2gig 20.1gig 18* Comparison of 3.1L 67 and HPO 3081k========================================
360/65 is nominal rated at something over .5mips (reg<->reg slightly under 1mic, reg<->storage start around 1.5mic and go up). running relocate increases 67 memory bus cycle 20% from 750ns to 900ns (with similar decrease in mip rate). 67 was non-cached machine and high I/O rate resulted in heavy memory bus (single-ported) contention with processor.
drums are ibm'ese for fixed head disks.
disk access is avg. seek time plus avg. rotational delay.
the 3.1l software is actually circa late 70 or earlier 71 (late in the hardware life but allowing more mature software). the 3081k software is the vm/hpo direct descendant of the cp/67 system.
90th percentile trivial response for the 67 system was well under a second, the 90th percential trivial response for the 3081k was .11 seconds (well under instantaneous observable threshold for majority of the people).
the page i/o numbers is sustained average under heavy load. actual paging activity at the micro-level shows very bursty behavior with processes generating page-faults at device service intervals during startup and then slowing down to contention rates during normal running. the 3081k system had pre/block page-in support (i.e. more akin to swap-in/swap-out of list of pages rather than having to individually page fault).
big change between 68 and 83 ... which continues today is that processor has gotten much faster than disk tech. has gotten faster. real memory sizes and program sizes have gotten much bigger than disk has gotten faster (programs have gotten 10-20 larger, disk get twice as fast, sequentially page faulting a memmap'ed region 4k bytes at a time takes 5-10 times longer). Also while current PCs are significantly more powerful than mainframe of late '60s and the individual disks are 5-10 times faster, the aggregate I/O thruput of todays PCs tend to be less than the aggregate I/O thruput of the mainframe systems.
In any case, when I started showing this trend in the late '70s that disk relative system performance was declining (i.e. rate of getting better was less than the getting better rate for the rest of the system) nobody believed it. A simple measure was that if everything kept pace, the 3081K system would have been supporting 2000-3000 users instead of 320.
Somewhat bottom line is that even fixed head disks haven't kept up with the relative system performance. Strategy today is whenever possible do data transfers in much bigger chunks than 4k bytes, attempt to come up with asynchronous programming models (analogous to weak memory consistency & out-of-order execution for processor models), and minimize as much as possible individual 4k byte at a time, synchronous page fault activity.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Multics and the PC Newsgroups: alt.os.multics Date: 15 Oct 1998 09:18:10 -0700... i've claimed that some Unix code (& bugs) that I worked on in the mid-80s looked an awful lot like stuff I replaced in CP/67 in the late-60s (which also shared a CTSS heritage); i.e. fixing the same darn set of bugs in almost the same code nearly 20 years later.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: lynn@garlic.com (Anne & Lynn Wheeler) Subject: X9.59 & AADS Newsgroups: gov.us.topic.ecommerce.standards Date: 17 Oct 1998 11:23:18 -0400Last week X9.59 left committee (X9A10, financial industry's working group on retail payments) last week and is on its way to vote as financial industry standard.
I also gave a presentation on AADS & X9.59 at PKI panel at NISSC. Last week, American Banker also had an article on AADS titled: Privacy Broker: Likely Internet Role for Banks? by Jeffrey Kutler.
Further information on AADS & X9.59 can be found at
https://www.garlic.com/~lynn/
A copy of the NISSC presentation has been posted to the X9A10 mailing list (ansi-epay@lists.commerce.net). A URL to the mailing list archive can be found at the garlic web pages.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Edsger Dijkstra: the blackest week of his professional life Newsgroups: alt.folklore.computers Date: 17 Oct 1998 14:36:00 -0700when I was an undergraduate ... I rewrote the drivers for 2702 for ASCII support ... in the 2702 there was a SAD command ... that theoretically allowed dynamically re-associated a line-scanner with a particular port (supporting 2741, 1050, tty/ascii, etc all with a single controller ... but different line scanner specific to type).
I got it setup so that when a dialed in terminal (or direct connected) first connected ... I would run thru terminal identification using different line-scanners ... and come up with the right answer. It all worked ... except IBM hardware engineer said that it shouldn't because of bug/feature of the 2702 that hired wired oscillator to specific port (i.e. while it was possible to switch line scanner ... it wasn't possible to switch the oscillator). Allowing tty/ascii terminals to come in on 2741 clocked ports (or the reverse) only marginally worked.
That resulted ... in part ... of four of us going off and building our own controller (somewhere we are supposedly credited with originating the IBM OEM controller business) ... where we would dynamically clock & identify incoming devices ... and handle some about of the normal full-duplex operation of tty devices.
360 channel/io was half-duplex. With the appropriate controller programming it was possible to use pairs of subchannel addresss to implement dual-simplex protocal (simulating full-duplex).
Much later, my wife & I ran skunk-works with projects like HSDT, HA/CMP, fiber-channel cluster scale-up, etc. For HSDT we built a high-speed backbone (we weren't able to bid NSFNET1 ... but did get a technical audit from NSF that stated what we had running was at least five years ahead of all bid submissions ... which were proposing building something new). For mainframe connects into HSDT, I implemented RFC1044 support in the standard product using pairs of subchannel addresses for dual-simplex convention. While the base product typically could sustained 44kbytes/sec, we ran RFC1044 support between 4341 and a Cray that ran sustained at 4341 channel hardware speed (mbyte/sec).
The original 3270 model was a 3277 ... while half-duplex and mostly dumb ... the controller operated at 640mbytes/sec, which somewhat masked some of the half-duplex/dump limitation ... except when the system went to write to the screen at the same time you were typing ... resulting in the keyboard getting locked. The remedy for that was a little fifo box ... you unplugged the keyboard from the display ... plugged the fifo box into the display and plugged the keyboard into the fifo box ... which would handle the problem with keyboard locking up when typing a character at the same moment the screen was being written to. Another problem was the key repeat function on the 3277 which was really slow ... opening up the keyboard ... it was possible to modify the keyboard to speed up the key repeat function .. a slight glitch was if you set the speedup to .1 seconds ... the screen refresh would fall behind ... and the screen update would continue for small period after stop pressing the key. Since that time ... I've periodically had to deal with terminals and/or GUIs where I couldn't get key repeat down to .1 seconds.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Edsger Dijkstra: the blackest week of his professional life Newsgroups: alt.folklore.computers Date: 17 Oct 1998 16:48:22 -0700the standard TCP/IP support used a controller that was essentially a pc/at with enet or t/r cards and a mainframe channel interface ... acting essentially as a bridge ... forcing the mainframe to do the IP<->MAC-layer work (significantly increasing its pathlength). for rfc1044 I had a real live router/gateway which cut the pathlength ... in addition providing much higher sustained bandwidth. the standard support, in addition to having low sustained thruput ... would have saturated a 3033 CPU long before it reach channel hardware bandwidth thruput.
another thing we did in HSDT was three layer architecture. They were bringing the IS executives from a large multi-national corporation into town for a dog&pony show in late '88 and I was asked to do HSDT presentation. I threw in the 3-layer architecture pitch and when they found out ... it drove the SSA, client/server, and T/R crowd crazy.
For the cost of 16mit t/r 300 desktop, client/server, mainframe attached configuration ... I did a 10mbit enet, 3-layer architecture, mainframe attached configuration with ten times the avg bandwidth delivered to the desktop and a couple middle layer apps.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Mainframes suck? (was Re: Possibly OT: Disney Computing) Newsgroups: alt.folklore.computers Date: 31 Oct 1998 18:00:24 -0800Many/most of the mainframes provided "batch" oriented services. Many/most of the open systems have tended towards interactive/online services. This has resulted in different implicit paradigm approach between batch and interactive/online paradigms.
For one thing ... interactive/online paradigms have tended to display messages to the user when something happens (paradigm assumes that there is somebody present); in the same situations batch paradigms tended to provide lots & lots of traps ... but if a trap hasn't been specified by the application program ... control will transfer to a system default handler.
Interactive/online paradigms tend to have better human engineering factors. The interesting thing is that the batch paradigm descendants tend to be better suited for deploying business critical, industrial strength web servers (allows better automation of exception conditions when the web servers don't have somebody constantly seated at the system).
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Multics Newsgroups: alt.folklore.computers,alt.os.multics Date: 08 Nov 1998 08:26:38 -0800>We bought a 360/67. Sigh.........
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: punch card editing, take 2 Newsgroups: alt.folklore.computers Date: 14 Nov 1998 16:33:53 -0800the other feature was that the 2540reader shared the middle stacker with the 2540punch .... application done for student registration .... was an edit check on whether registration &/or card read was correct .... cards were read one at a time into the middle stacker .... and if correct a blank card was punched into the middle stacker behind the card with problems. The punch hopper was loaded with different colored stock than cards being read.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: qn on virtual page replacement Newsgroups: comp.arch Date: 19 Nov 1998 19:09:05 -0800typically replacement tasks that walk the page tables do local LRU type algorithms and replacement tasks that walk the reverse table do global LRU type algorithms.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Multics Newsgroups: alt.folklore.computers Date: 07 Dec 1998 23:15:06 -0800summer after first programming intro class when I was a sophomore ... they would left me have the machine room to myself from 8am sat. until 8am monday .... 48hr straight thru shift (initially only a 709, 1401, and a 360/30 ... plus misc. other things ... made it a little hard to make a monday morning summer school class). I quickly acquired the habit of first thing cleaning all the tape drives, card reader, and card punch ... before even bothering to proceed. For those 48 hrs ... everything in the room was my personal computer ... had to develop habit of going w/o sleep for 50-60hr stretches. nothing substitutes for hands on experience (and it also beats washing dishes in cafeteria)
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Earliest memories of "Adventure" & "Trek" Newsgroups: alt.folklore.computers Date: 09 Dec 1998 08:14:21 -0800I remember hearing about this new thing that had been done at stanford within the previous 2-3 months ... and I searching for a copy. About 2 weeks later somebody from overseas sent me fortran source thru a round-about network path. I put it up on some of the large mainframe nodes and it started being played on 3270s. within another six weeks ... several random people from around the world on the internal network were sending me binary copies of this new thing they had stumbled across (that I had deployed; the internal network was larger the arpanet thruout its history up thru the mid-80s). Another six weeks and I was being sent versions ported to PLI with added rooms and points (typically another 150-200 points).
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Reliability and SMPs Newsgroups: comp.arch Date: 09 Dec 1998 08:46:52 -0800in previous life, my wife owned the responsibilty for loosely-coupled and wrote the architecture for what (some number of years later) became parallel sysplex. we ran skunk works in late 80s that originated HA/CMP (and had huge pushback from many people that are out hawking clusters now). One way of looking at lpars is significnatly expanded virtual machine hardware assist under control of the service processors (which have tended to be mini-VM systems themselves).
did lots of work also on SMP versions (worked with the guy that originated C&S ... spent 3 months coming up with mnemonic that were his initials).
problem has been that it is hard to make everything perfect ... so eventually migrate from fault-free to fault-tolerant; fault-tolerant looks at recovery and fencing ... lots of fencing is much more difficult with shared resources (i.e. like software bugs eventually accounting for 99% of faults).
the other is simple things like loading new version of operating system. early on we looked at operation that had 5 minute outage/year (1-800 lookup). Loading new operating system tended to require minimum of 30-60 minutes per year.
both software fault handling and operating system maintenance tend to rely on some sort of memory fencing.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Reliability and SMPs Newsgroups: comp.arch Date: 09 Dec 1998 11:25:22 -0800example was cluster with HIPPI switch interconnect ... needed protocol in switch to address fencing an apparently failed processor (i.e. say a processor that stalls a couple instructions before an I/O write to shared, high-integrity resource) as well as help with deadlocked race condition. got HIPPI switches that could be used to fence and help with deadlock.
--
Anne & Lynn Wheeler | lynn@garlic.com, finger for pgp key
https://www.garlic.com/~lynn/
From: Anne & Lynn Wheeler <lynn@garlic.com> Subject: Re: Ok Computer Newsgroups: alt.folklore.computers Date: 31 Dec 1998 14:06:24 -0800it is possible that during the NSFNET1/NSFNET2 phase ... it was only $.20 on the dollar ... i.e. commercial contributions to NSFNET1/NSFNET2 in excess of price/contract. In any case, NSFNET1/NSFNET2 would then be viewed as a temporary aberration ... something that was significantly a commercially subsidized incubater for new bandwidth utilization paradigms and technologies ... in hopes of creating demand that would eventually show return for the original investment.
... post from another mailing list ...
To: dcsb@ai.mit.edu
Subject: Re: dbts: More on law vs economics
.... somebody once told me that chip volume curve goes to $.10/chip.
the other part of some of the new technology is communications. I've
frequently hypothesized that the current infrastructure was created by
a couple billion in dark fiber being made available to the internet
infrastructure at something like 10 cents on the dollar. This created
huge financial opportunity for organizations to develop applications
that could take advantage of the difference between the value of the
dark fiber and its going cost within the internet infrastructure (say
$5 billion in dark fiber .... going for $500m .... would mean that
there is theoretical $4.5 billion aggregate business opportunity for
internet based offerings).
There is then possible 2nd order effects with respect to the $4.5b
seed that comes about from paradigm shifts & scale (increase use by
100* and increase perceived value returned ... and there is reasonable
probability that original investment in the fiber could be recouped).
Again many of the new technology paradigms are dependent on huge
financial aggregations ... both because of capital costs associated
with computers & chip infrastructures ... as well as current capital
intensive communication infrastructures.
... snip ...
and from some archive ....
Date: 10/22/82 14:25:57
To: CSNET mailing list
Subject: CSNET PhoneNet connection functional
The IBM San Jose Research Lab is the first IBM site to be registered on
CSNET (node-id is IBM-SJ), and our link to the PhoneNet relay at
University of Delaware has just become operational! For initial testing
of the link, I would like to have traffic from people who normally use
the ARPANET, and who would be understanding about delays, etc.
If you are such a person, please send me your userid (and nodeid if
not on SJRLVM1), and I'll send instructions on how to use the
connection. People outside the department or without prior usage of
of ARPANET may also register at this time if there is a pressing need,
such as being on a conference program committee, etc.
CSNET (Computer Science NETwork) is funded by NSF, and is an attempt
to connect all computer science research institutions in the U.S. It
does not have a physical network of its own, but rather is a set of
common protocols used on top of the ARPANET (Department of Defense),
TeleNet (GTE), and PhoneNet (the regular phone system). The
lowest-cost entry is through PhoneNet, which only requires the
addition of a modem to an existing computer system. PhoneNet offers
only message transfer (off-line, queued, files). TeleNet and ARPANET
in allow higher-speed connections and on-line network capabilities
such as remote file lookup and transfer on-line, and remote login.
... snip ... top of post, old email index, HSDT email
(Sorry if you got this message twice, separate mailinglists...)
(If you get this, you are obviously on the list already...)